End-to-End Control Model (Production): Originals → Chunking → Embeddings → Vector DB → Updates/Deletions
Enterprise principle
A RAG system does not “own” original files. It reflects systems-of-record (SharePoint, Confluence, Drive, CMS).
The indexing pipeline is a governed mirror: automated by triggers/jobs, supervised by owners and ops, and fully auditable.
1) What is chunk.text (and what it is not)
What it is
- Human-readable text (a string) representing the meaning of a portion of the source.
- Extracted/transcribed/OCR’d from the original, then normalized (remove headers/footers, preserve headings, clean bullets).
- The retrieval unit you embed, store, retrieve, and cite.
What it is not
- Not a byte-for-byte representation of a PDF/DOCX/PNG/MP4.
- Not raw binary, not pixels, not audio frames.
- Vector DB is not file storage; originals remain in the source repository.
Example chunk record (conceptual):
{
"chunk_id": "SEC-POL-012:3.2:0007",
"text": "Section 4.2 — Access Control Requirements ...",
"metadata": {
"doc_id": "SEC-POL-012",
"version": "3.2",
"section": "Access Control",
"status": "Active",
"access_tags": ["Security","IT","GRC"],
"source_uri": "sharepoint://.../SEC-POL-012.pdf#page=14"
}
}
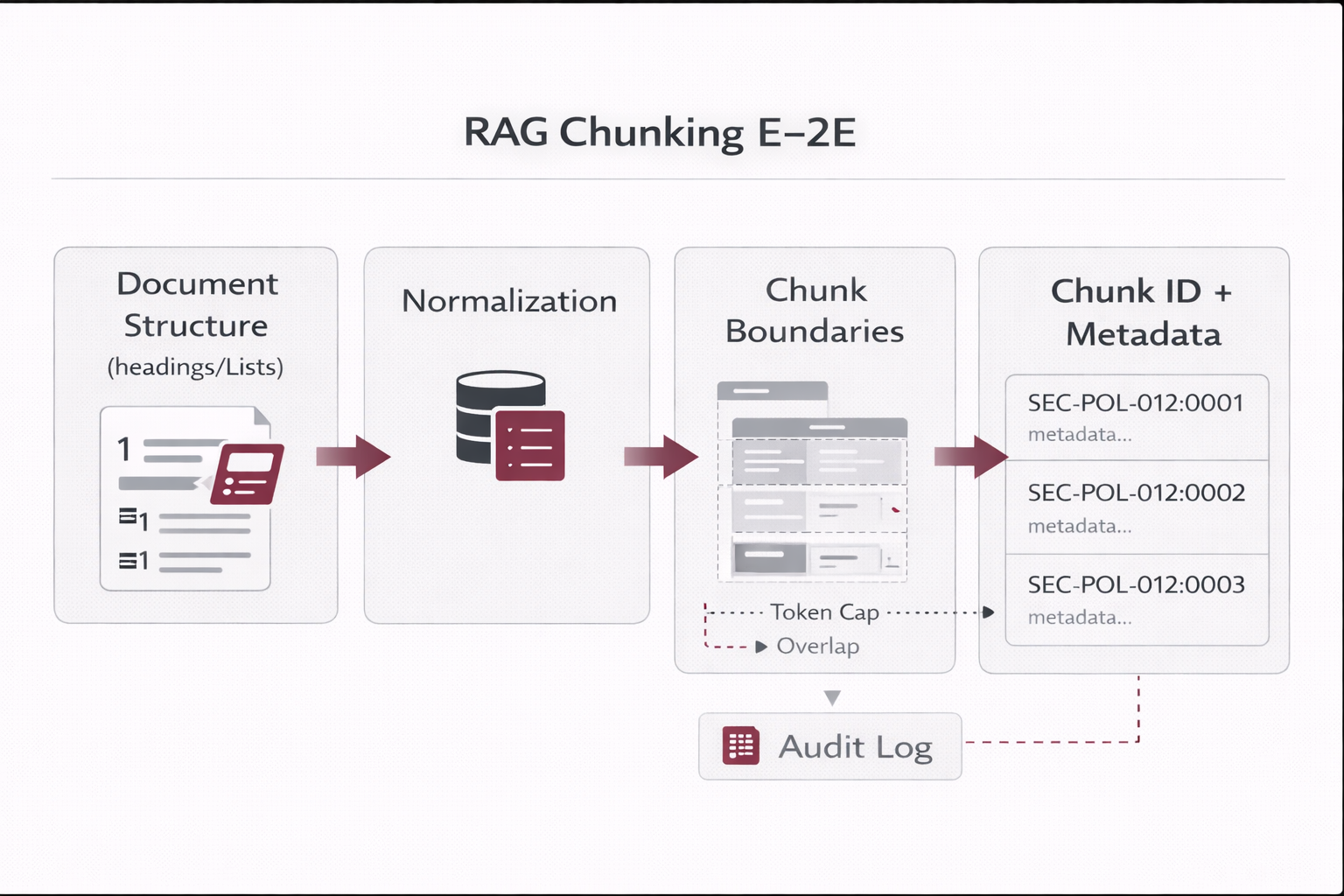
2) Chunking: how chunks are created (tools + profiles + rules)
Chunking is one of the strongest quality levers. Production chunking preserves structure (headings, steps, tables),
uses controlled chunking profiles, and assigns stable identifiers for updates and auditability.
2.1 Practical tool stack
| Source type |
Extraction approach |
Chunking approach |
| PDF (native text) |
Unstructured / PyMuPDF / pdfplumber |
Heading-aware + token cap (profile-based) |
| DOCX |
docx parser (e.g., python-docx) / Unstructured |
Section-aware + keep lists intact |
| HTML / Wiki |
HTML parser (e.g., BeautifulSoup) |
Split by H2/H3 + token cap |
| Scanned PDFs / Images |
OCR (Azure Vision / Google Vision / Tesseract) |
Chunk by paragraphs/blocks + page metadata |
| Audio/Video |
Speech-to-text transcription |
Chunk by topic/time window + timestamps |
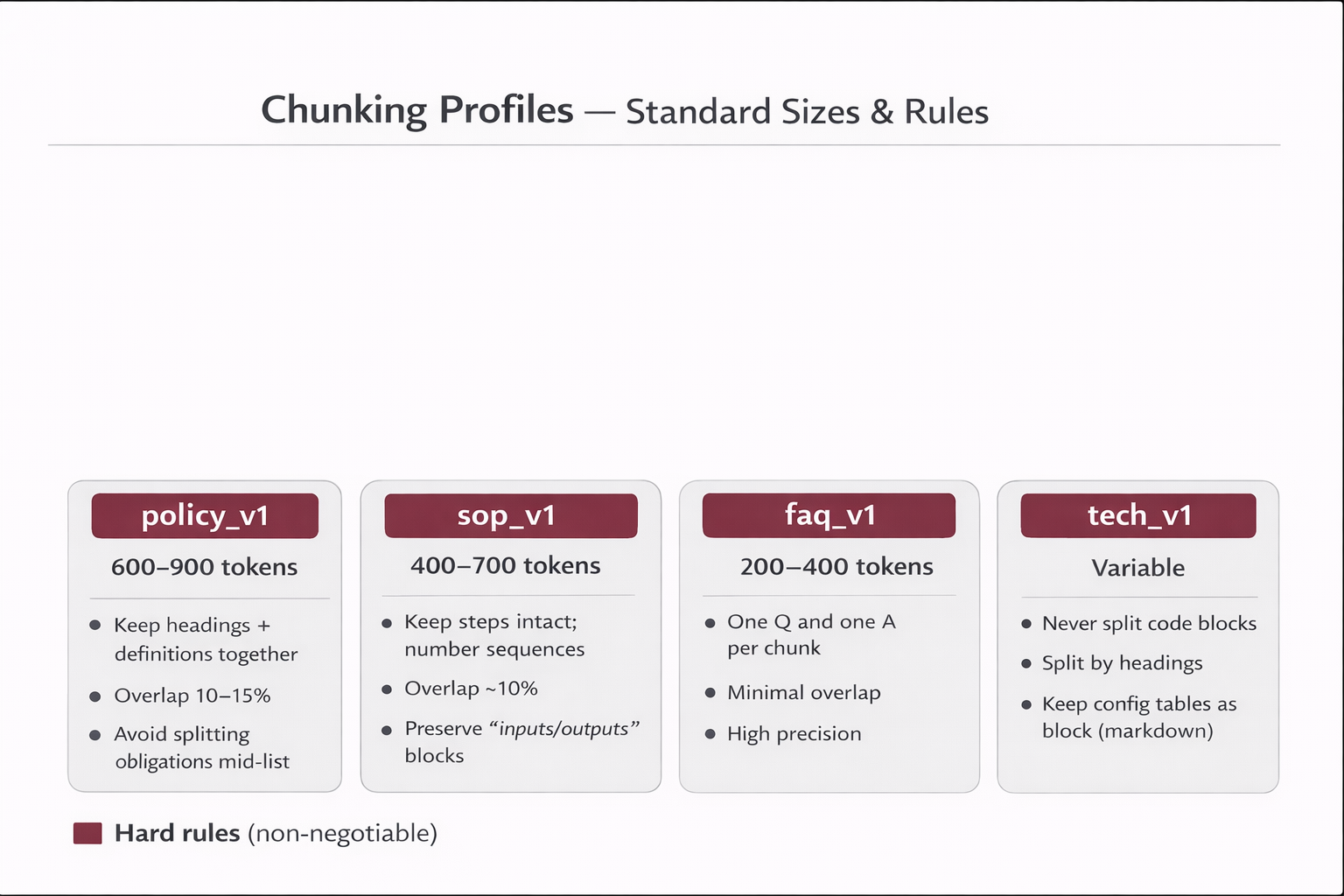
2.2 Chunking profiles (controlled evolution)
Profiles prevent random tweaks. You only change chunking through versioned profiles, then measure impact via evaluation gates.
| Profile |
Target docs |
Chunk size |
Hard rules |
| policy_v1 |
Policies |
600–900 tokens |
Keep headings + definitions together; overlap 10–15%; avoid splitting obligations mid-list. |
| sop_v1 |
SOPs |
400–700 tokens |
Keep steps intact; keep numbered sequences; overlap ~10%; preserve “inputs/outputs” blocks. |
| faq_v1 |
FAQs |
200–400 tokens |
One Q + one A per chunk; minimal overlap; maximize precision. |
| tech_v1 |
Technical docs |
Variable |
Never split code blocks; split by headings; keep config tables as a single block (markdown). |
3) Embeddings & Vector DB: who stores what (and where)
Critical clarification
The embedding model does not store your chunks. It only returns a vector.
Your indexing service/job performs the upsert into the Vector DB using its SDK/API.
Indexing flow (conceptual):
1) chunk.text → embedding_model → vector
2) vector_db.upsert(
id=chunk_id,
vector=vector,
payload={ text, metadata }
)
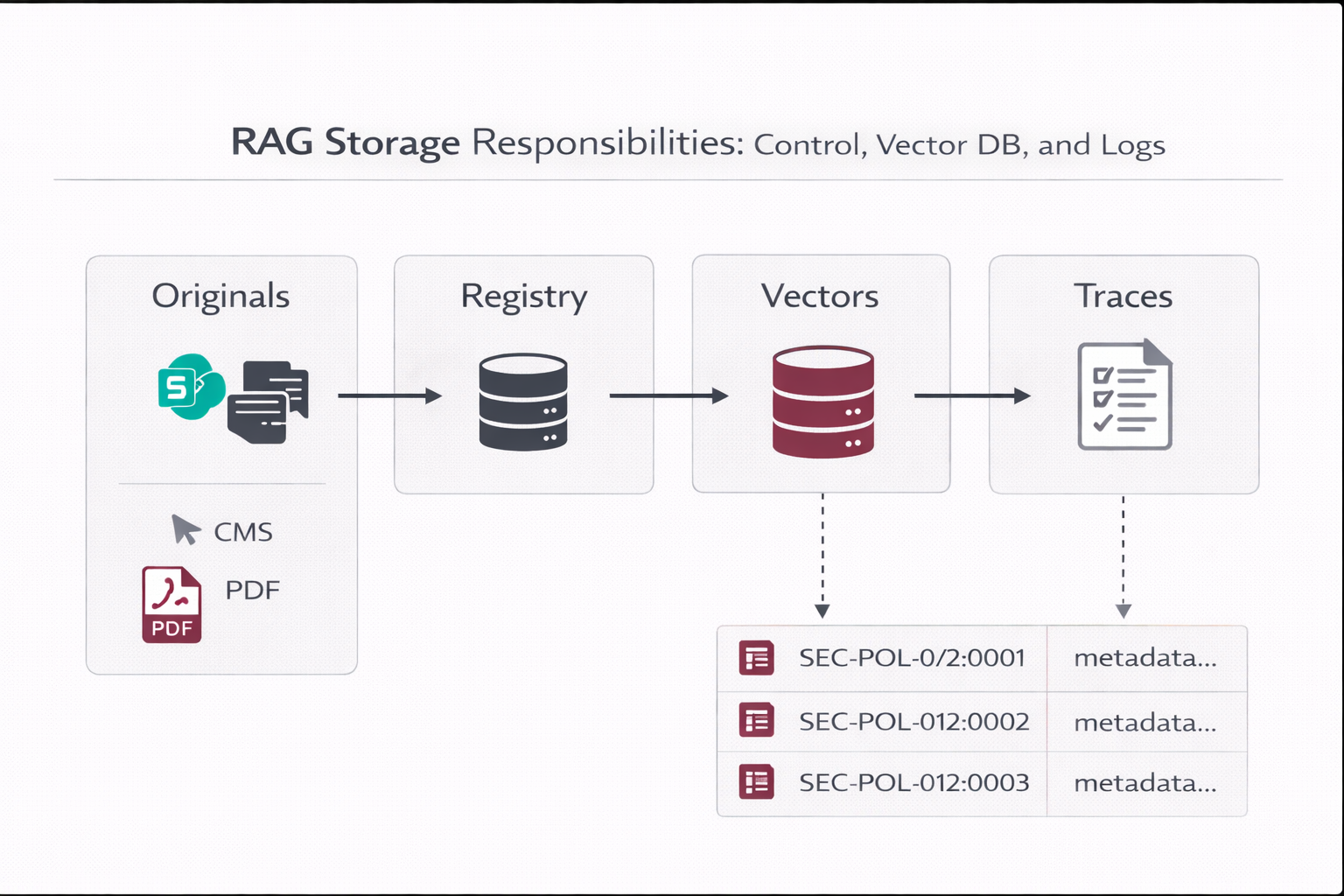
3.1 What lives where
| Asset |
System of record |
Why |
| Original files (PDF/DOCX/PNG/MP4) |
SharePoint/Drive/CMS/Object storage |
Retention, enterprise ACLs, audit/legal, click-through to source. |
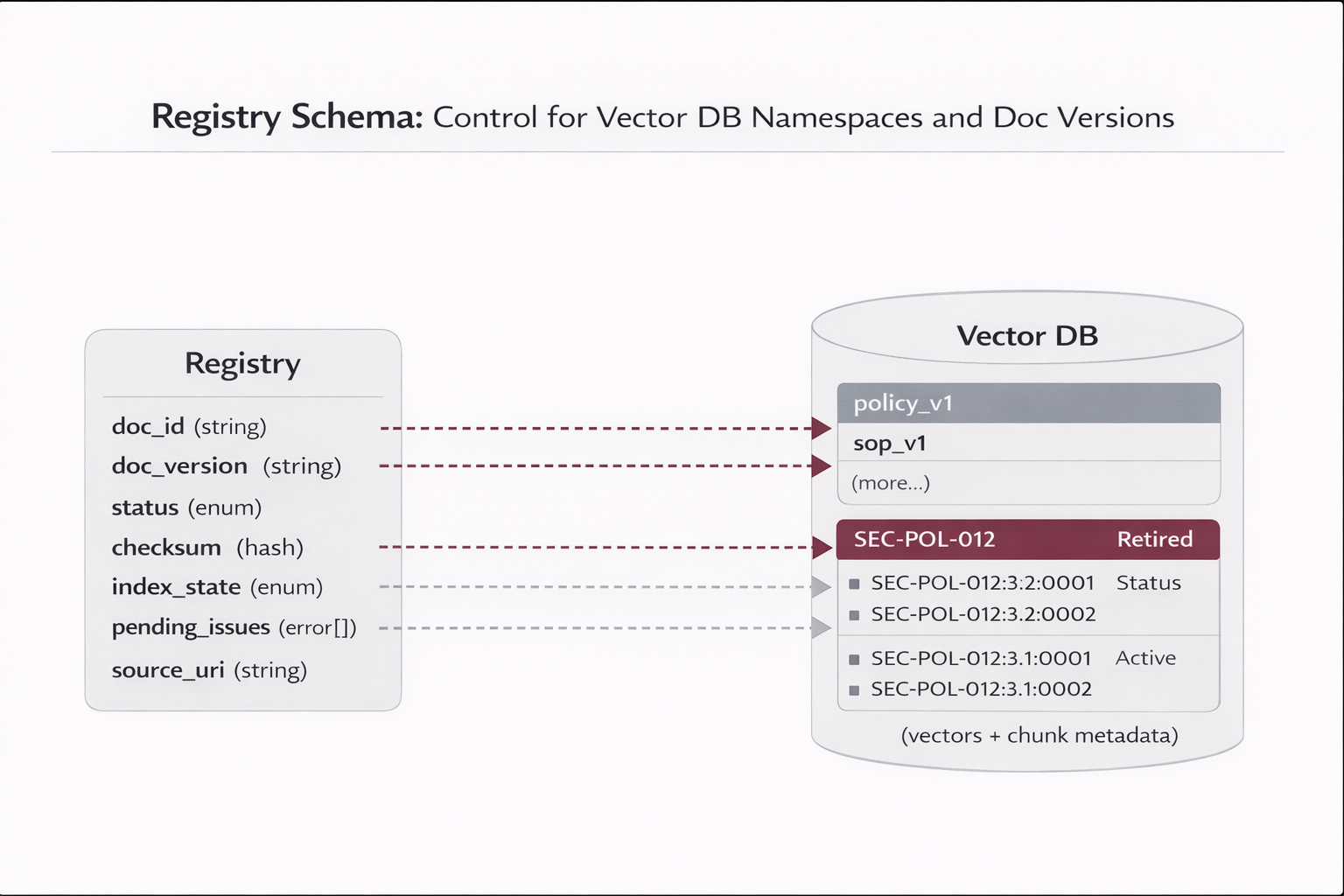
| Registry (doc lifecycle, checksums, config) |
Relational DB (MySQL/Postgres) |
Operational truth for delta ingestion, retries, rollbacks, reproducibility. |
| Vectors + chunk payload |
Vector DB (Qdrant/Pinecone/Chroma/pgvector) |
Fast semantic retrieval + metadata filtering (ACL, lifecycle, tenant). |
| Traces & feedback |
Relational DB / log store |
Audit trail, debugging, continuous evaluation, governance evidence. |
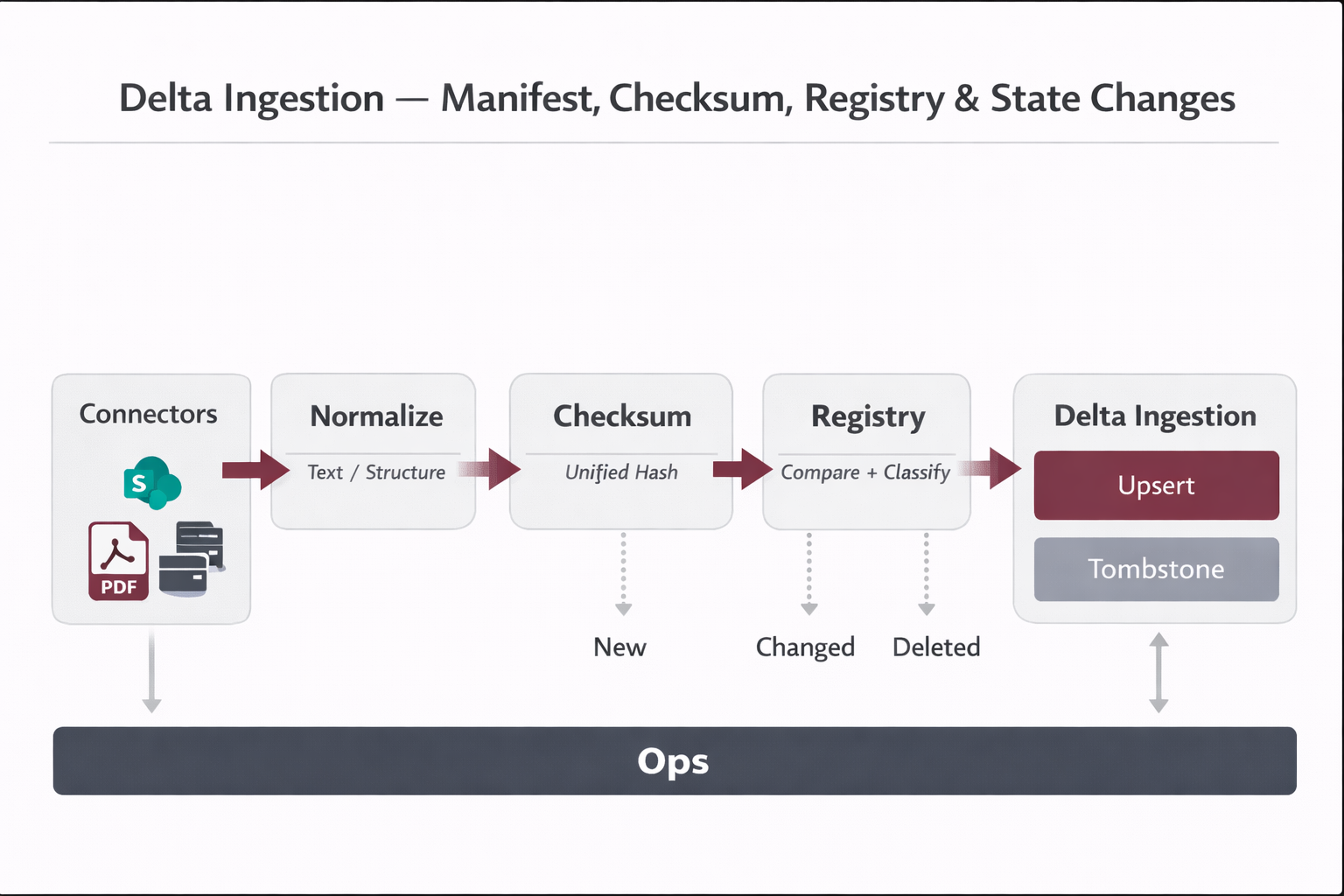
4) Updates & deletions: delta ingestion, tombstones, and hard deletes
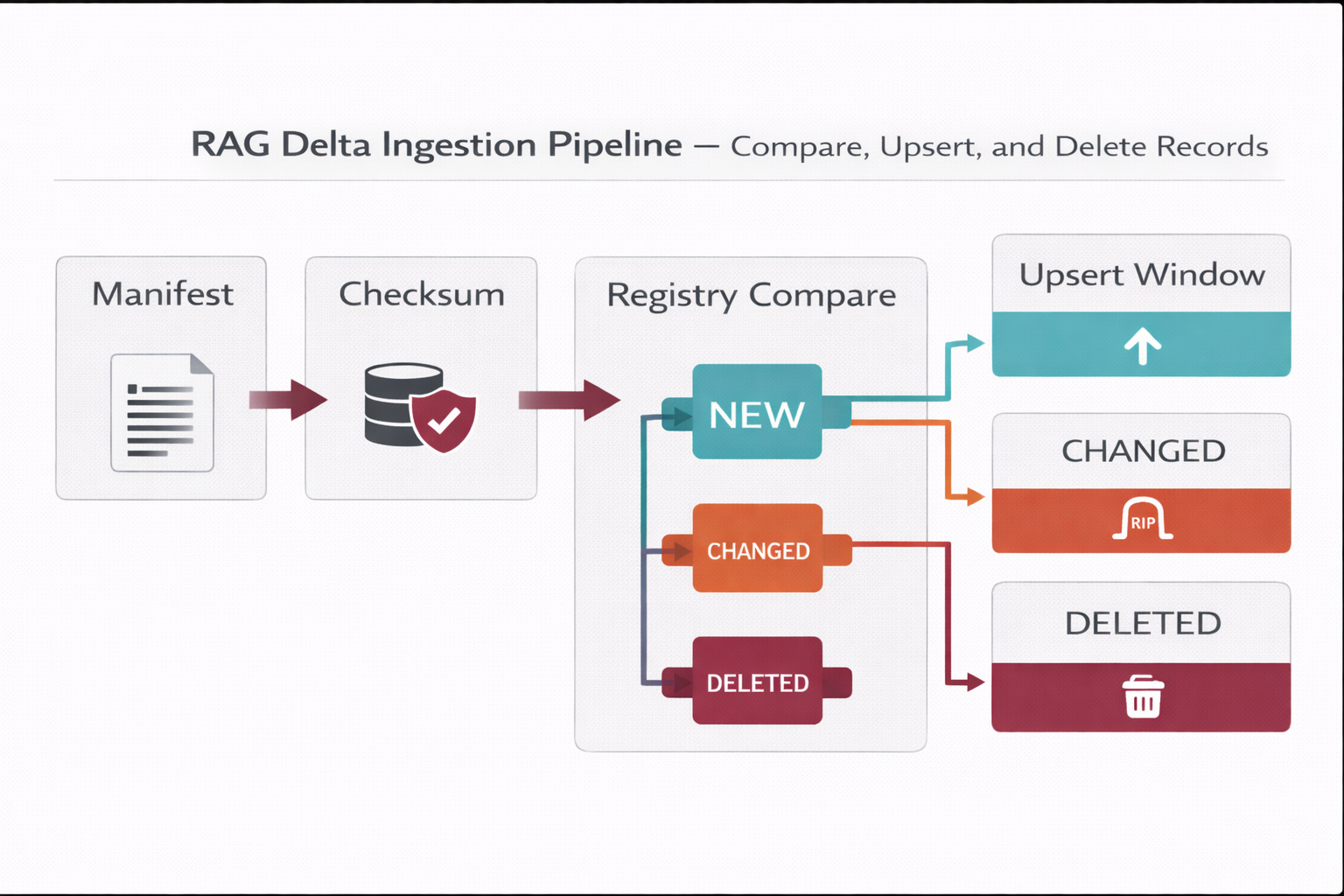
4.1 Delta ingestion (healthy updates without reindex-all)
- Connectors collect a manifest: doc_id, last_modified_at, source_uri, access_tags.
- Compute a checksum (hash) of normalized content (optionally per section).
- Compare to the registry; process only: new, changed, deleted.
- Upsert new vectors; mark old chunks tombstoned when versions change.
- Record index_state and errors for automated retries.
Why checksum matters
It prevents accidental “reindex all,” controls cost, and keeps indexing pipelines predictable.
4.2 Versioned IDs (find, update, and rollback)
Recommended ID strategy:
doc_id = stable identifier (SEC-POL-012)
doc_version = semantic or timestamp (3.2 or 2025-11-02T18:11Z)
chunk_id = doc_id + ":" + doc_version + ":" + chunk_seq
Examples:
SEC-POL-012:3.1:0007 (older)
SEC-POL-012:3.2:0007 (newer)
4.3 What happens when a physical file is deleted?
The correct approach is automated and governed. People decide lifecycle and ownership; systems execute the pipeline.
Deletion is detected via webhooks or polling, then applied as a soft delete (tombstone) followed by controlled hard delete.
| Step |
System action (automated) |
Outcome |
| 1 |
Detect deletion: event (e.g., file.deleted) OR polling sees doc missing |
Registry marks doc as Retired / PENDING_DELETE |
| 2 |
Apply tombstones: find chunks by doc_id and set is_deleted=true (or status Retired) |
RAG stops retrieving that content immediately |
| 3 |
Hard delete window (weekly/monthly): physically delete tombstoned vectors |
Storage cleanup + governance-compliant retention |
| 4 |
Audit record: log who/when/source/what (traceability) |
Defensible evidence trail for compliance |
5) Who triggers updates? Webhooks vs polling vs governance actions
| Pattern |
How it triggers |
When to use |
| A) Webhooks (near real-time) |
Source emits events (created/updated/deleted) to the indexing service |
Best when supported; lowest lag for updates. |
| B) Polling (scheduled scan) |
Connector lists docs every X hours; compares registry (checksum) |
Most common in enterprise; robust when events are unavailable. |
| C) Human governance (exceptions) |
Owner changes lifecycle state/effective date; system applies indexing rules |
Regulated docs, sensitive policies, emergency takedowns. |
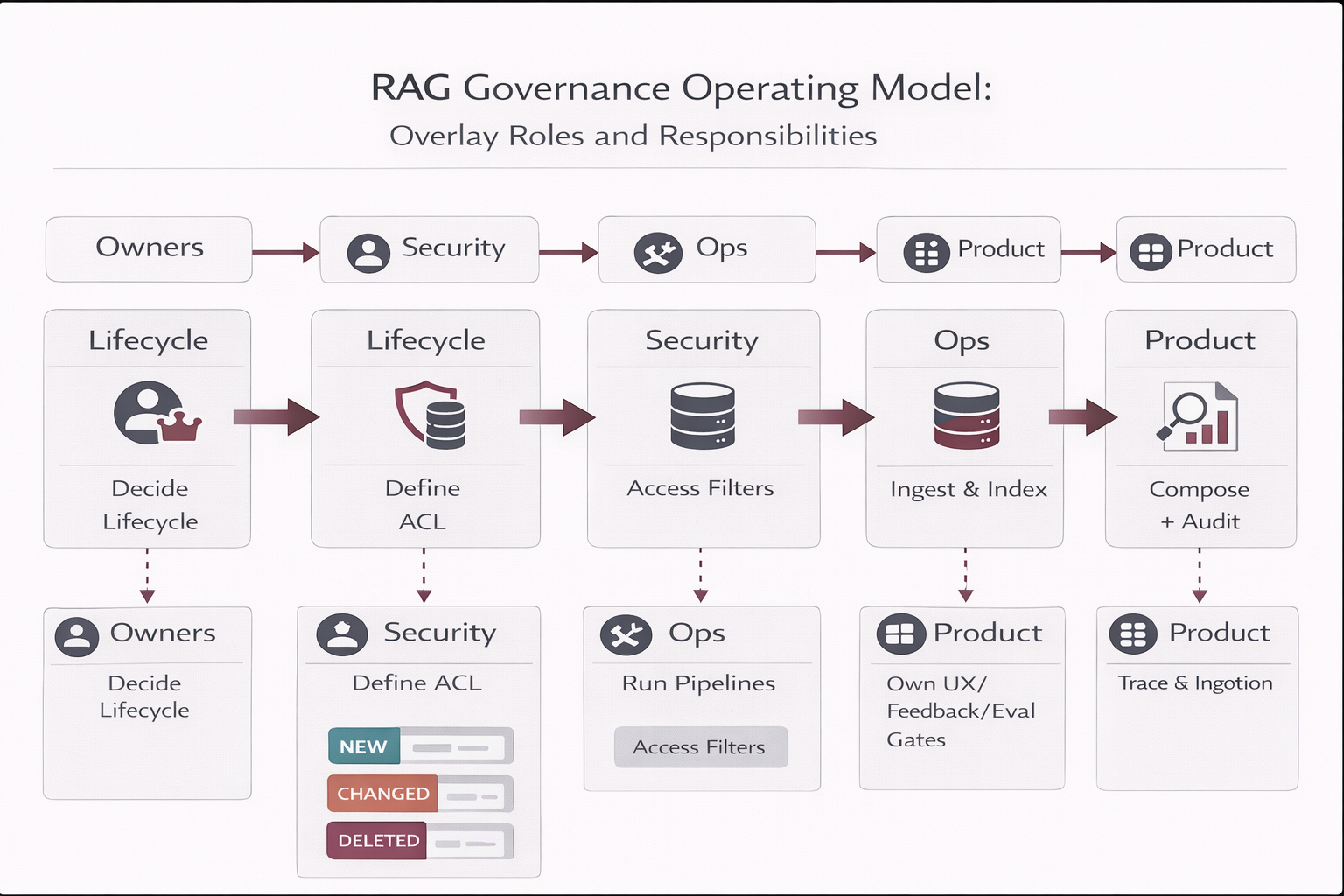
Best practice
People control policy and lifecycle state (Draft/Active/Deprecated/Retired). The system controls execution (chunk, embed, upsert, tombstone, delete).
6) Governance & Operating Model (mapped control + RACI)
6.1 Governance mapping (who owns what)
| Area |
Accountability |
Typical roles |
| Knowledge ownership |
Accuracy, approvals, effective dates, lifecycle state |
Policy Owner (Security/HR/PMO), Document Steward |
| Platform operations |
Connectors, indexing pipeline, retries, monitoring |
RAG Ops / MLOps / Platform Engineering |
| Security & risk |
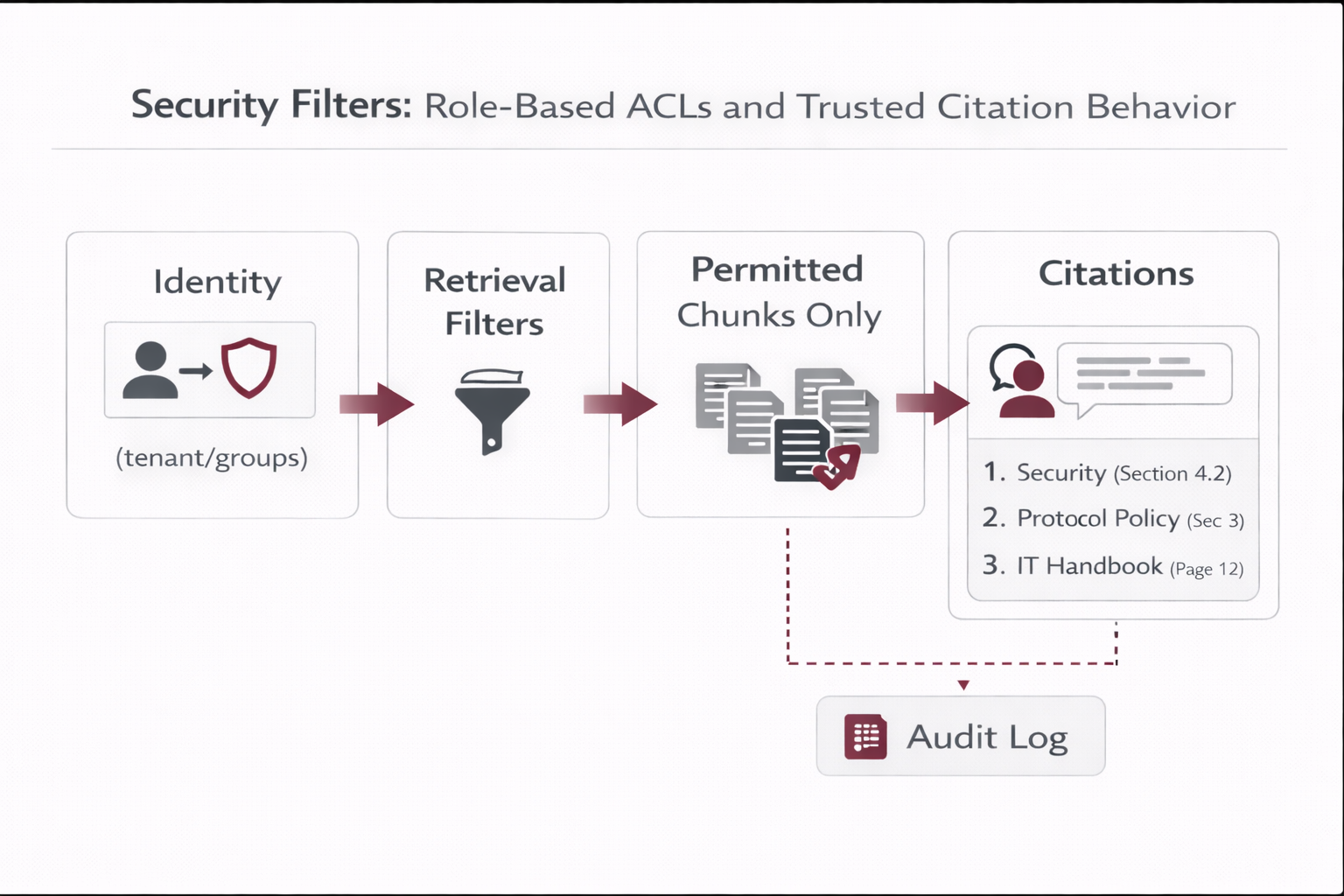
ACL model, least privilege, audit requirements |
Security, GRC, IAM |
| Product / UX |
Citations UX, feedback loops, adoption |
Product, UX, Enablement |
6.2 RACI (minimum viable)
| Activity |
Doc Owner |
RAG Ops |
Security/GRC |
Product |
| Approve doc & set lifecycle state |
R/A |
C |
C |
I |
| Connector configuration (sources, scopes) |
C |
R/A |
C |
I |
| Delta ingestion execution (chunk/embed/upsert) |
I |
R/A |
C |
I |
| ACL model & enforcement |
C |
R |
A |
I |
| Deletion handling (tombstone + hard delete) |
C |
R/A |
C |
I |
| Evaluation gates & regression suite |
C |
R |
C |
A |
6.3 Operating cadence (what runs automatically)
Automated (system)
- Webhook processing or polling scan
- Checksum compare (delta ingestion)
- Chunk → embed → upsert
- Tombstones on version change or deletion
- Retries + alerts on failures
Human oversight (governance)
- Document approvals & lifecycle state changes
- Monthly review of top cited docs and “no-answer” gaps
- Security review of ACLs and sensitive domains
- Sign-off for re-chunking or embed-model migrations
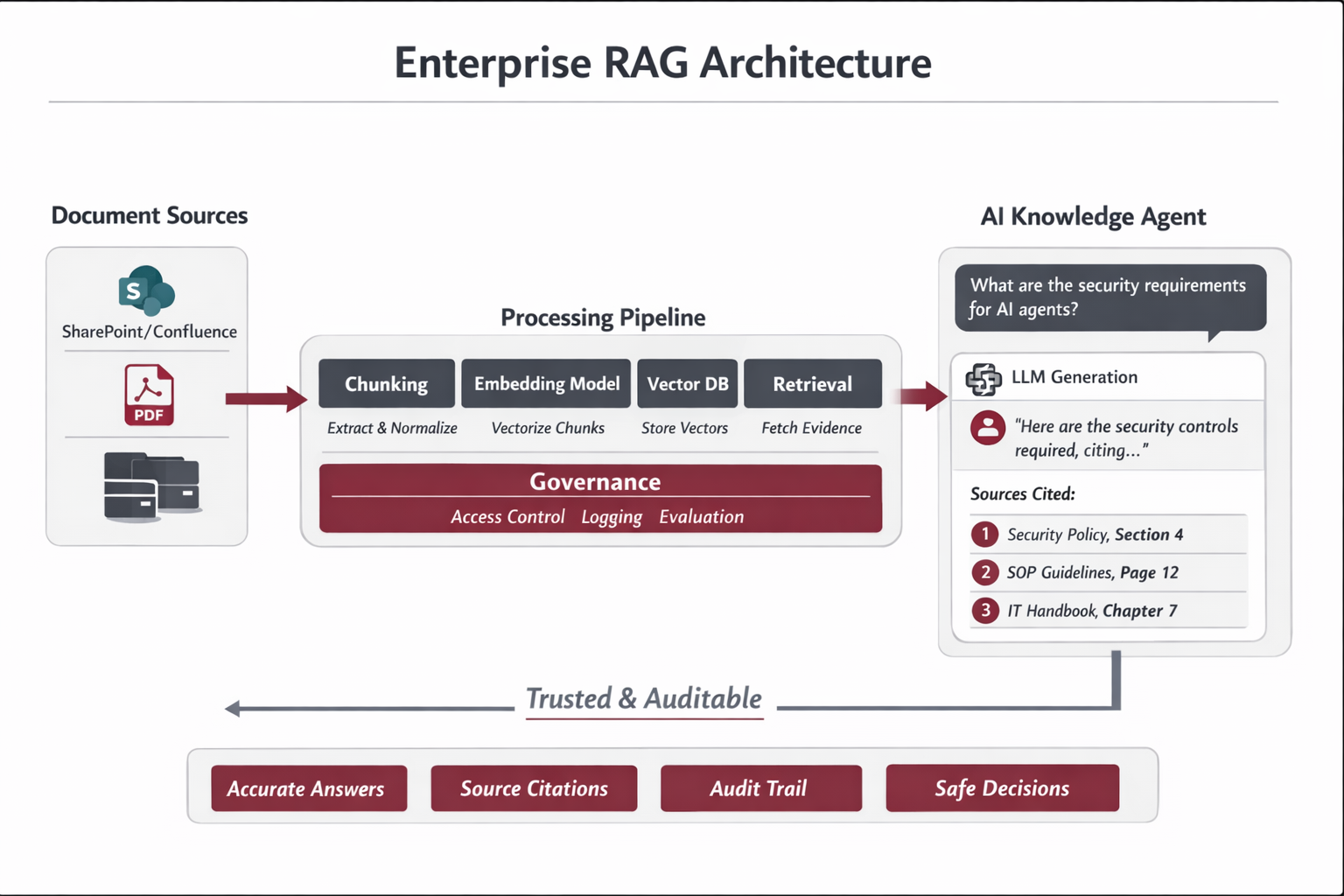
7) Architecture description (end-to-end control)
End-to-end system (descriptive):
Sources of Record (SharePoint/Confluence/Drive/CMS)
→ Connector (webhook listener or polling scanner)
→ Normalization (clean text + structure)
→ Registry (checksums, lifecycle, config, state)
→ Chunking (profile-based, stable IDs)
→ Embedding model (returns vectors)
→ Vector DB (upsert vectors + payload; ACL metadata)
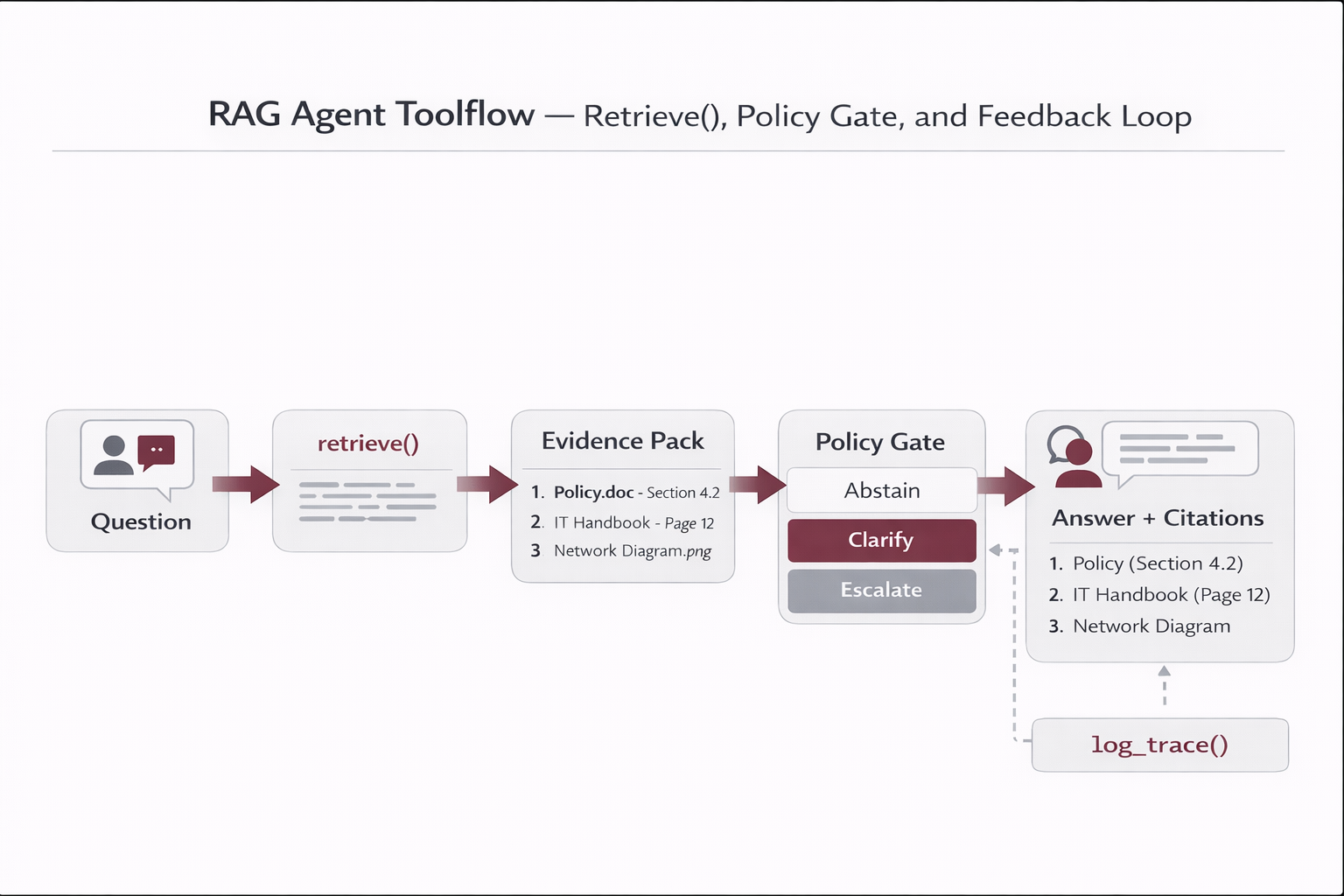
→ Retrieval (ACL filters + freshness + lifecycle penalties)
→ LLM Answer (evidence-only + citations)
→ Trace logs + feedback (audit + evaluation)
→ Ops dashboard (health, lag, cost, quality)
Suggested images to generate
rag_chunking_e2e.png
rag_storage_responsibilities.png
rag_delta_ingestion_deletions.png
rag_governance_operating_model.png