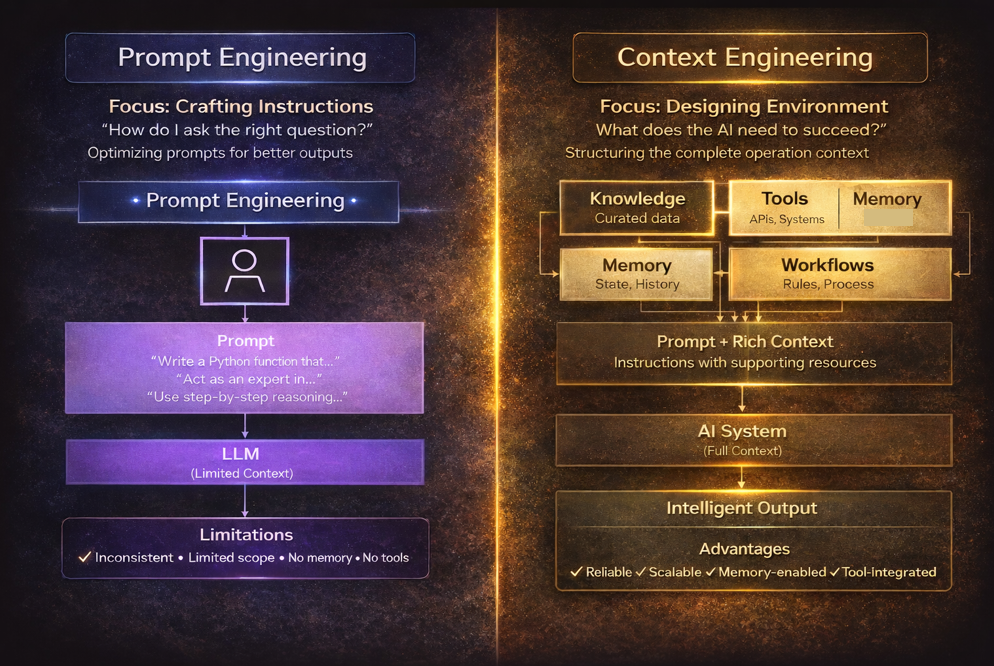
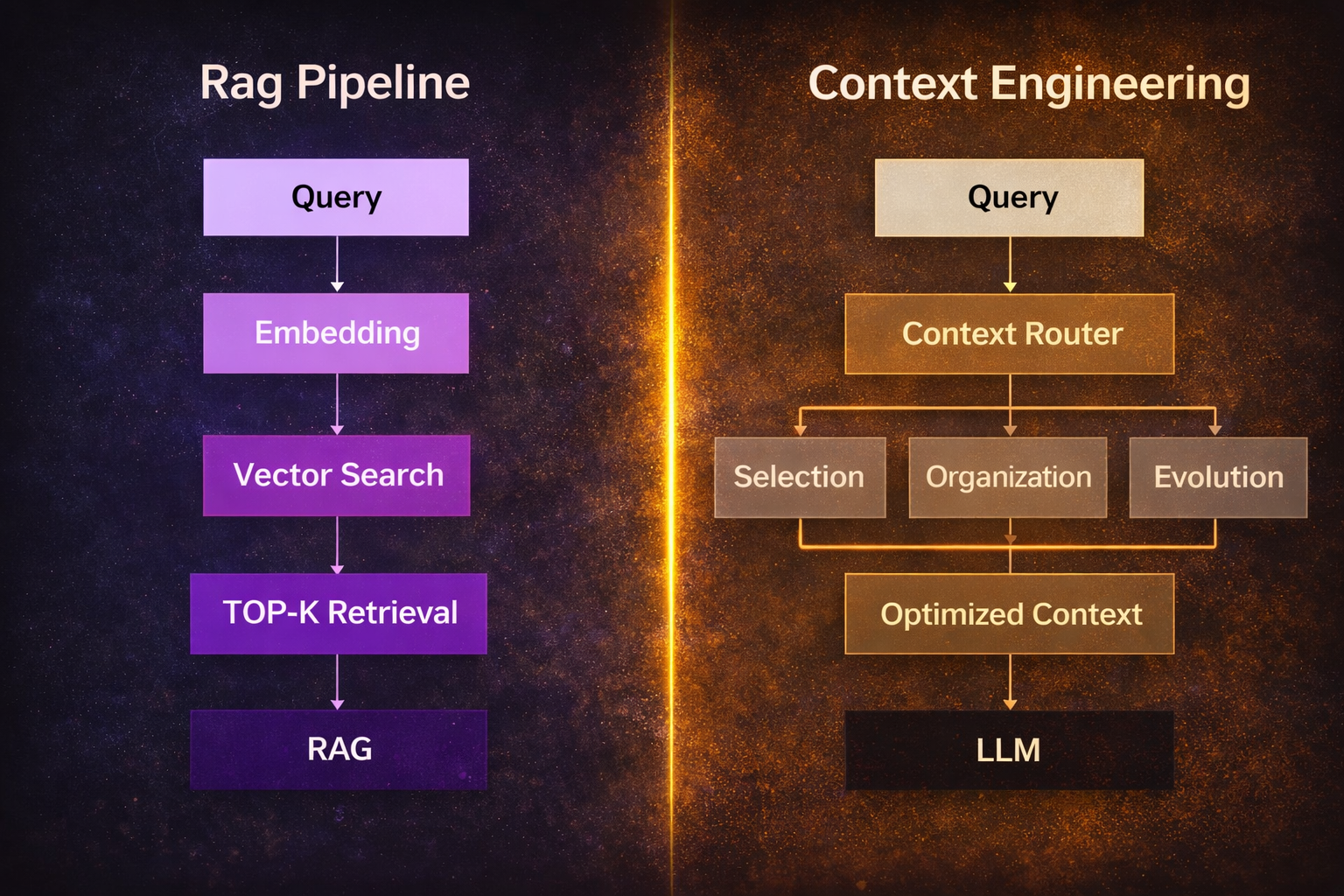
4 Examples you can reuse
Below are agentic-ready templates that show the difference between “prompting”
and “engineering the context the agent needs.”
Example 1 — Prompt template for an agentic task
Task prompt (drop-in template)
Copy
SYSTEM (stable):
You are an execution-focused AI agent. Follow policies. If missing data blocks correctness, ask for it.
Prefer short, structured outputs. Use tools when needed.
DEVELOPER (stable):
Output must match the requested schema. Cite sources when you use retrieved evidence.
Never invent identifiers, dates, or quotes.
USER / TASK (variable):
Goal: {one sentence objective}
Context: {what the user already decided + constraints}
Inputs: {files, links, data, system state}
Definition of Done:
- {acceptance criterion 1}
- {acceptance criterion 2}
Output format:
- {sections or JSON schema}
Quality checks:
- {e.g., "verify totals", "include assumptions"}
Example 2 — Context pack for a “budgeting assistant” agent
Context engineering bundle (what you attach alongside the prompt)
Copy
CONTEXT PACK (assembled at runtime)
1) Policies
- Allowed advice scope (finance/legal disclaimers)
- Safety constraints
2) State
- User locale, currency, current month, known accounts
- Last computed budget and assumptions
3) Retrieval (RAG)
- Relevant policy docs, prior notes, verified rates
- Each snippet has: source_id, timestamp, excerpt
4) Tools
- get_transactions(account_id, date_range)
- categorize_transactions(list)
- forecast_cashflow(history, horizon)
- Each tool includes schema + examples + error cases
5) Token budget plan
- Instructions: 10%
- State: 15%
- Retrieval evidence: 35%
- Working space: 10%
- Final answer: 30%
Example 3 — Agentic “verify then finalize” pattern
This is a common pattern for making agents more dependable: the model produces a draft,
then runs a verification step with explicit checks (often deterministic), and only then finalizes.
Two-pass agent pattern
Copy
PASS 1 (Draft):
- Produce output quickly using current context.
- Mark uncertainties explicitly.
PASS 2 (Verify):
- Run checklist:
• Are required fields present?
• Are numbers internally consistent?
• Are claims supported by provided evidence?
• Did we respect constraints (tone, length, exclusions)?
- If any check fails: retrieve missing context OR ask a targeted question.
- Then produce final output.
Pitfall to avoid
- Don’t hide critical facts in long retrieved blobs; summarize and cite.
- Don’t let tool schemas drift—version them and test calls.
- Don’t treat memory as truth—treat it as hypotheses unless verified.