1 — AI Agents: Two Reference Families + 5 Practical Architectures
AI Agents: Two Reference Families + 5 Practical Architectures
AI Agents: Two Reference Families + 5 Practical Architectures
AI agents are rapidly moving from experimental demos to core operational components inside modern organizations. As this shift accelerates, one of the biggest challenges is not the model itself, but conceptual confusion: what exactly is an “AI agent,” how autonomous should it be, and how should it be designed in practice?
Purpose of this guide
This page provides a shared vocabulary and a set of deployable reference designs.
We start with the two most common reference families used in industry to talk about agents, then translate them into
five practical architectures you can teach, evaluate, and implement safely.
Why two reference families exist
The term “AI agent” is used in two complementary ways. Mature teams keep both views because they answer different questions:
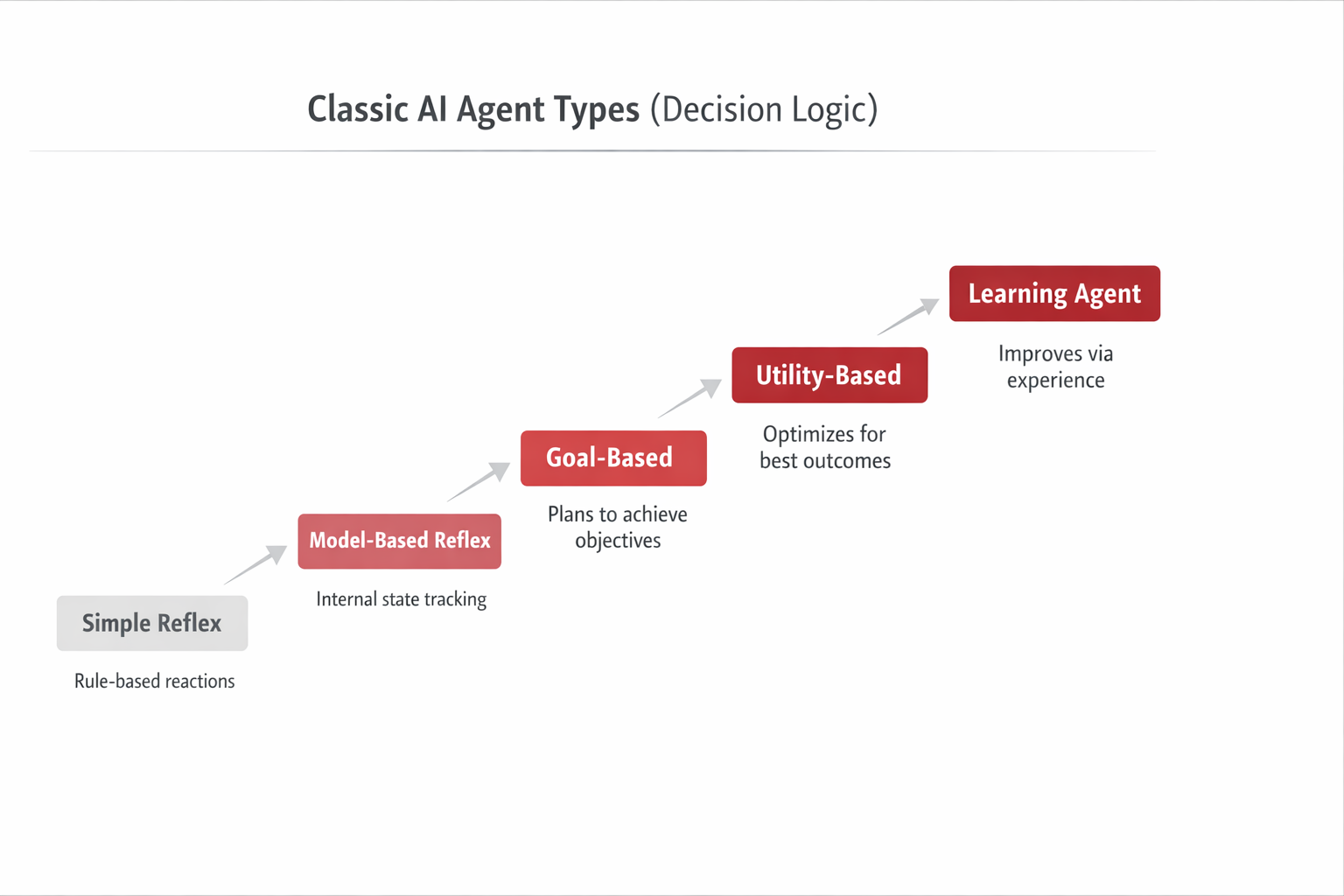
Family A — Classic Agent Taxonomy (Theory)
Classifies agents by how they decide (reactive rules, internal state, goal reasoning, utility optimization, learning).
It is stable, technology-agnostic, and useful for discussing capability levels and autonomy.
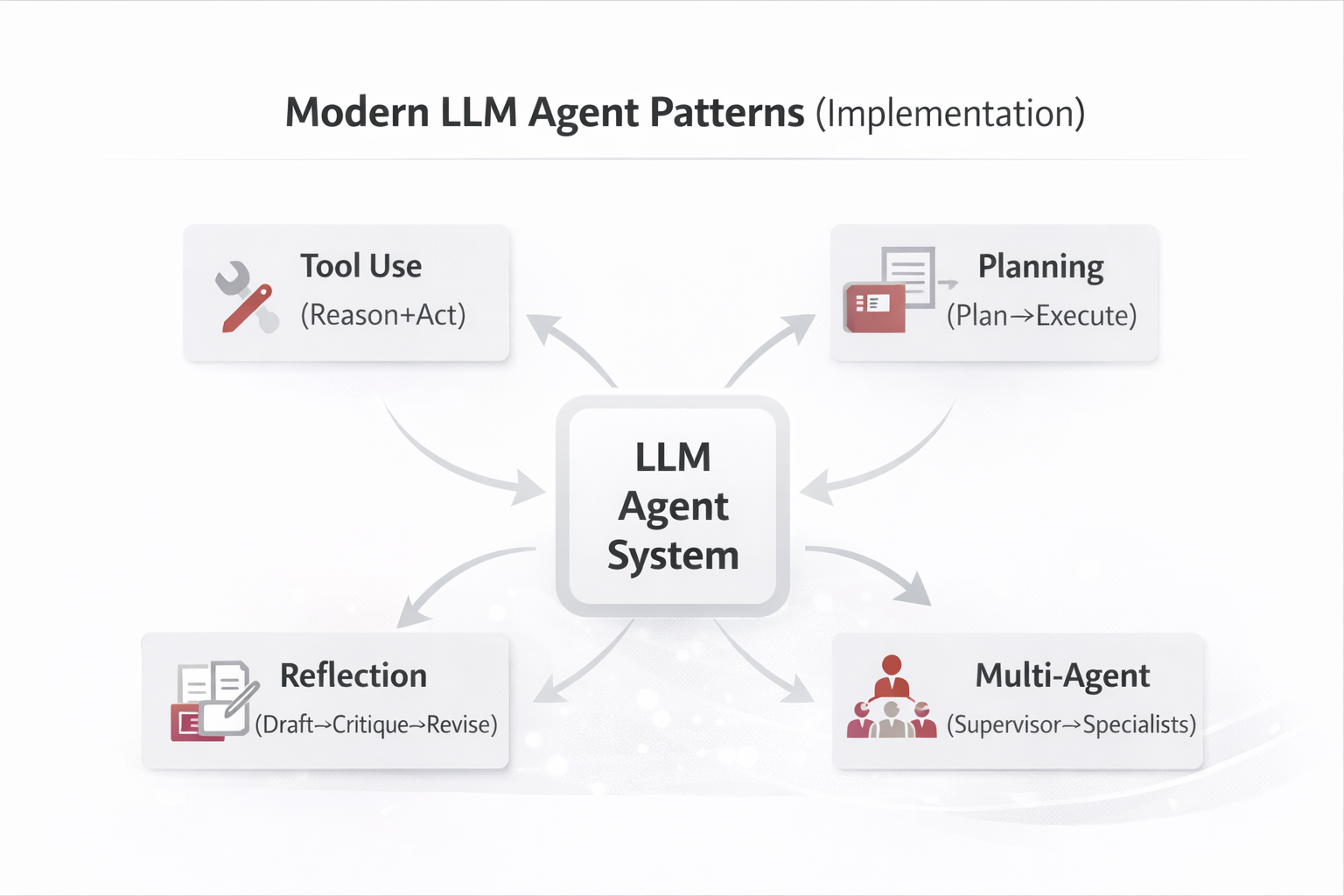
Family B — Modern LLM Agent Patterns (Implementation)
Focuses on how agents are built in real products using LLMs:
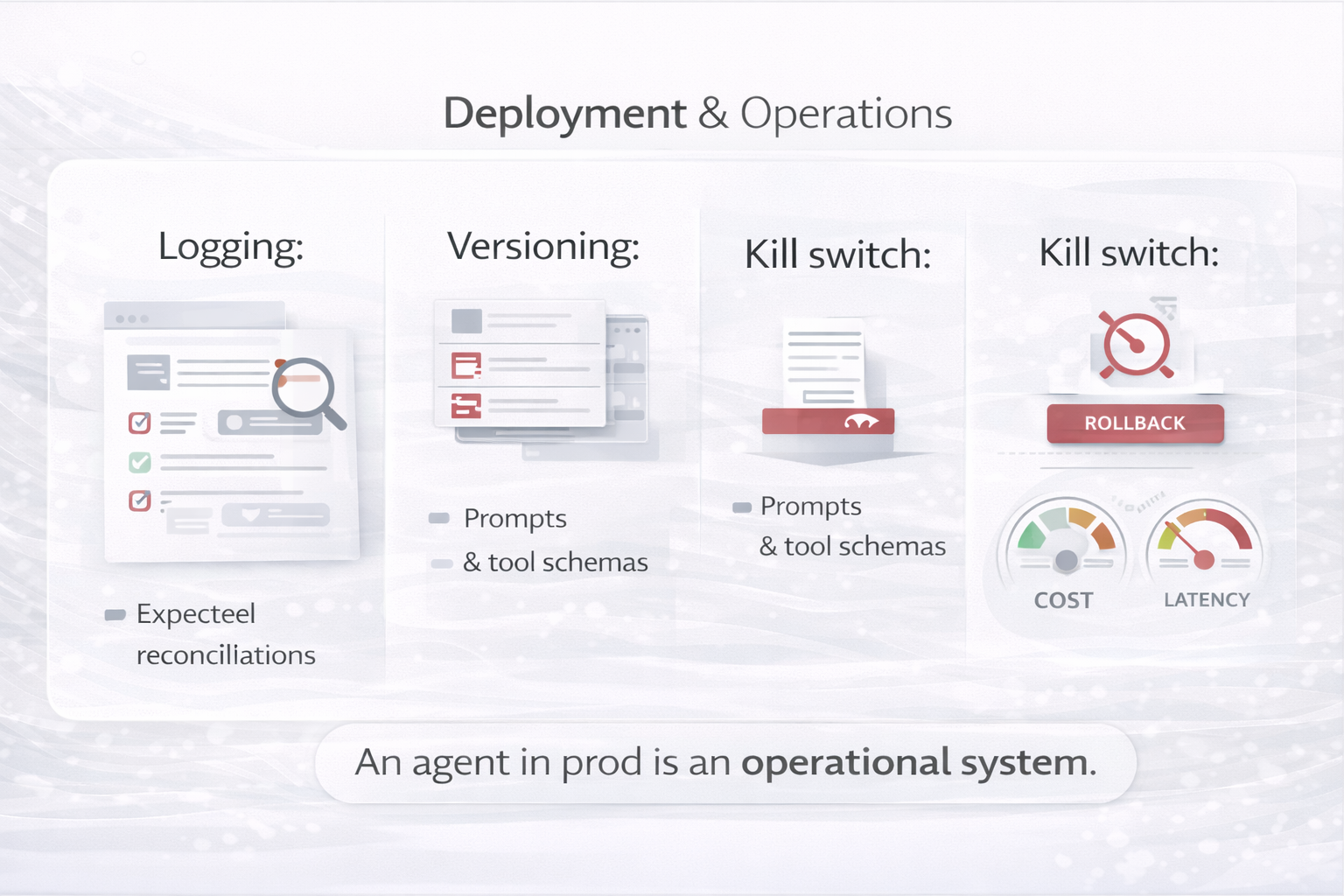
tool use, planning, reflection, and multi-agent coordination—plus guardrails, observability, and governance.
How to use this in a session
- Use Family A to set expectations about autonomy (what “level” of agent you actually need).
- Use Family B to teach implementation building blocks (how you achieve reliability, safety, and scalability).
- Then select from the five practical architectures based on task characteristics (single-step vs multi-step, policy grounding, high-stakes quality, parallel expertise).
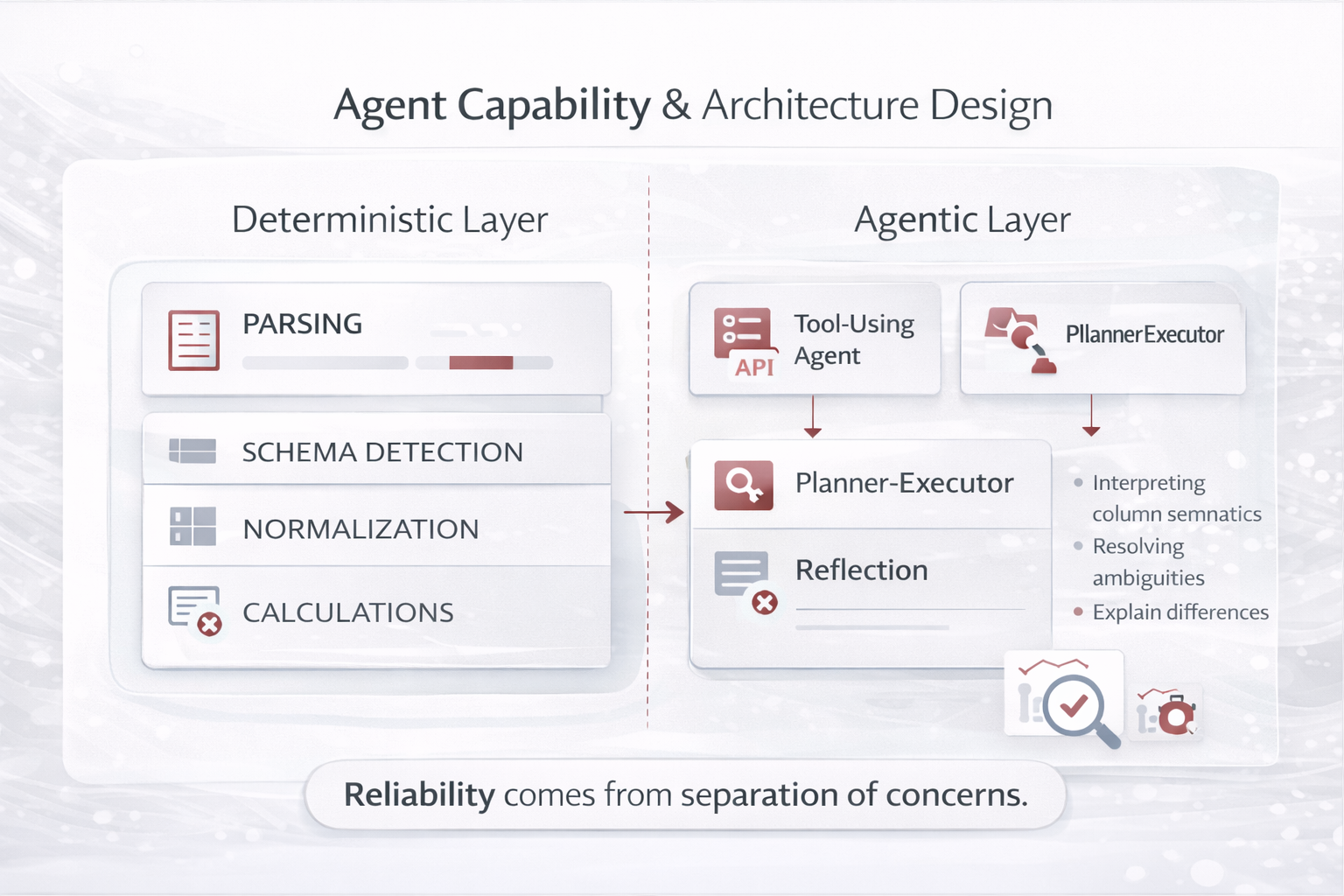
- Emphasize that real-world systems are usually hybrids: for example, a Planner–Executor agent may also use RAG for grounding and a bounded reflection loop for quality.
Key takeaway
Classic AI theory helps you define what kind of agent you are building (capability and autonomy).
Modern LLM patterns help you implement that agent as a reliable, governable system.
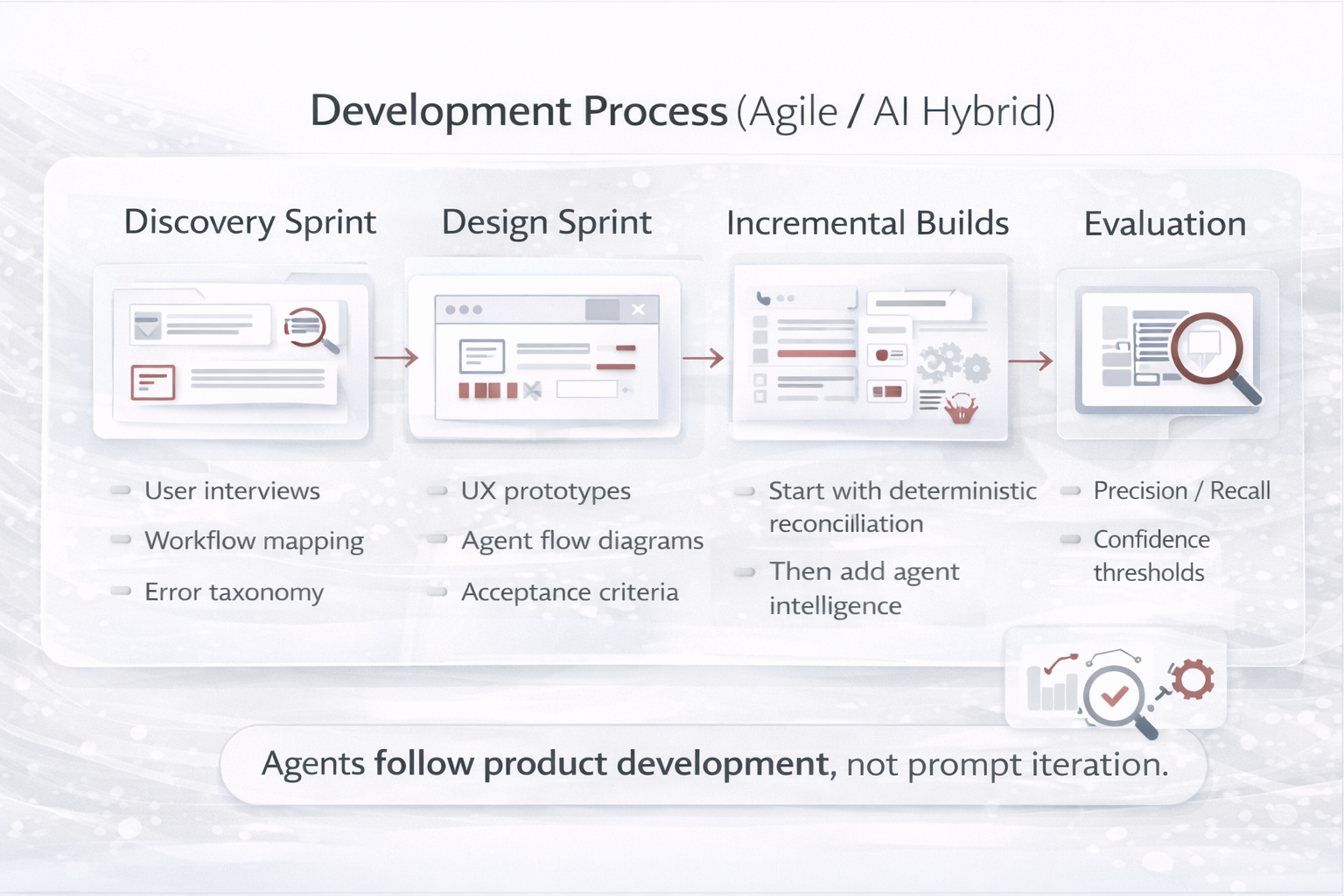
The strongest teams use both perspectives to avoid “prompt-only” solutions and build agents people can trust.
References (Industry + Research)
| Source | Type | Why it’s relevant |
|---|---|---|
|
IBM — “What are AI agents?”
https://www.ibm.com/topics/ai-agents
|
Documentation / Explainer | Practical enterprise framing of AI agents, autonomy, and where agents fit in real business workflows. |
|
Russell & Norvig — Artificial Intelligence: A Modern Approach
Classic AI textbook reference
|
Foundational theory | Widely used reference for classical agent taxonomies (reflex, model-based, goal-based, utility-based, learning). |
|
ReAct (Reason + Act)
Paper / pattern commonly cited in industry
|
Research anchor | A key basis for tool-using agent behavior: interleaving reasoning and actions with external tools. |
|
Reflexion (Reflection loops)
Paper / pattern commonly cited in industry
|
Research anchor | Formalizes critique-and-revise loops to improve reliability and reduce errors through bounded iteration. |
|
AWS — Agentic AI design patterns (video sessions)
Training / conference videos
|
Industry video | Clear coverage of tool use, planning, reflection, and multi-agent collaboration patterns, with architecture-level explanations. |
Fast selection guide
| If your task is... | Choose | Why |
|---|---|---|
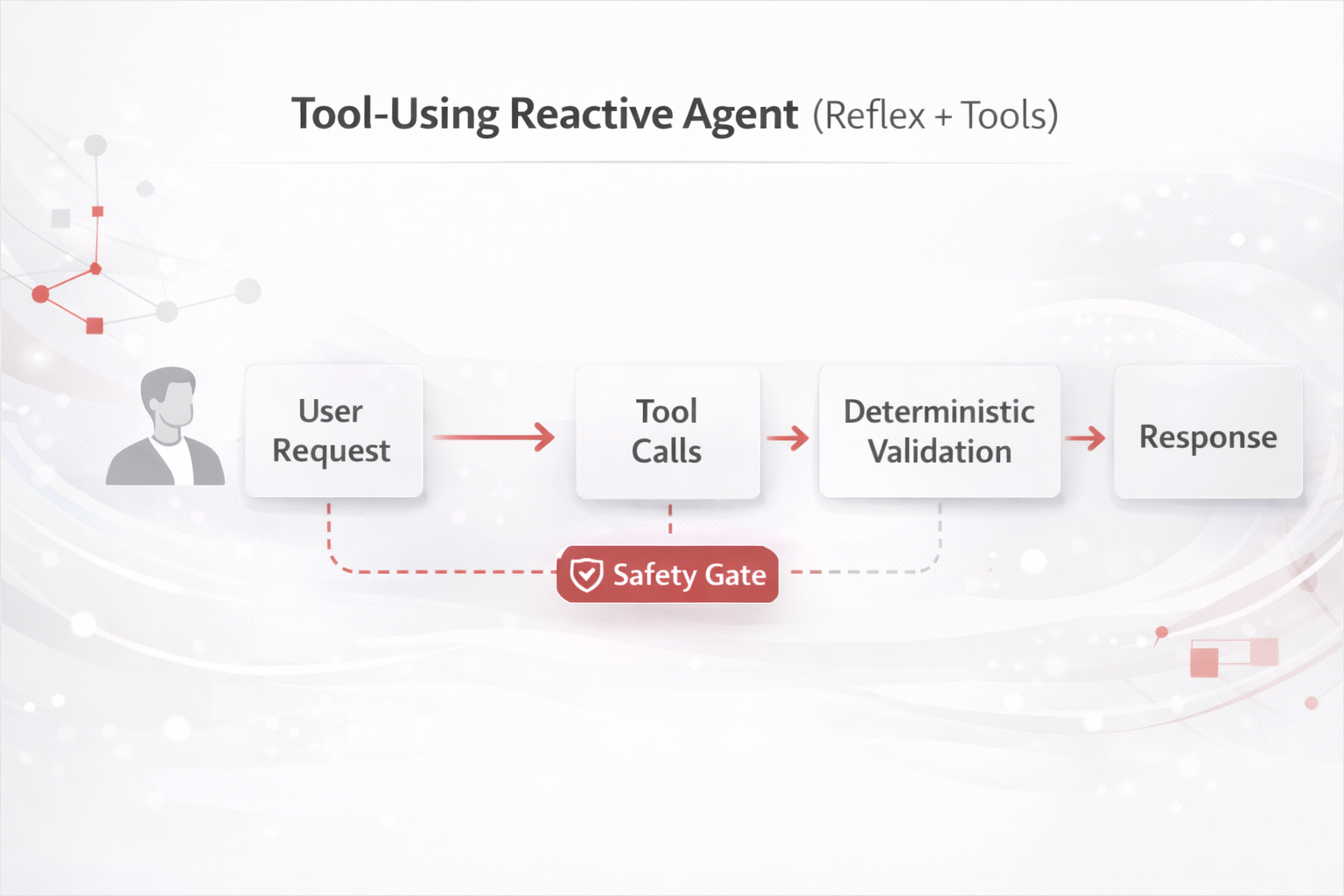
| Single-step action with tools | 1) Reactive + Tools | Lowest overhead; fast throughput; deterministic validation is easy. |
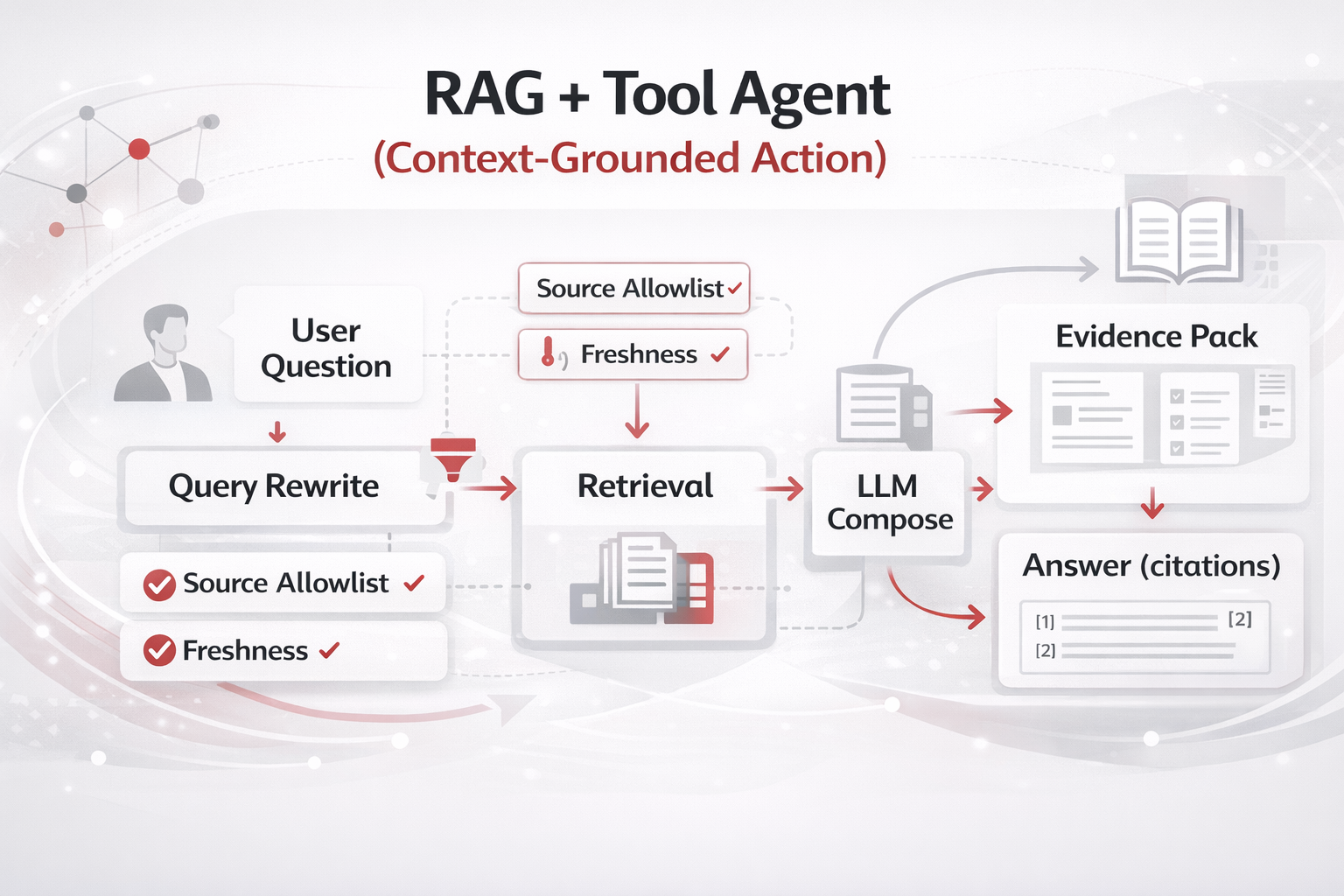
| Policy/procedure heavy or “must be grounded” | 2) RAG + Tools | Reduces hallucinations; makes answers defensible via sources. |
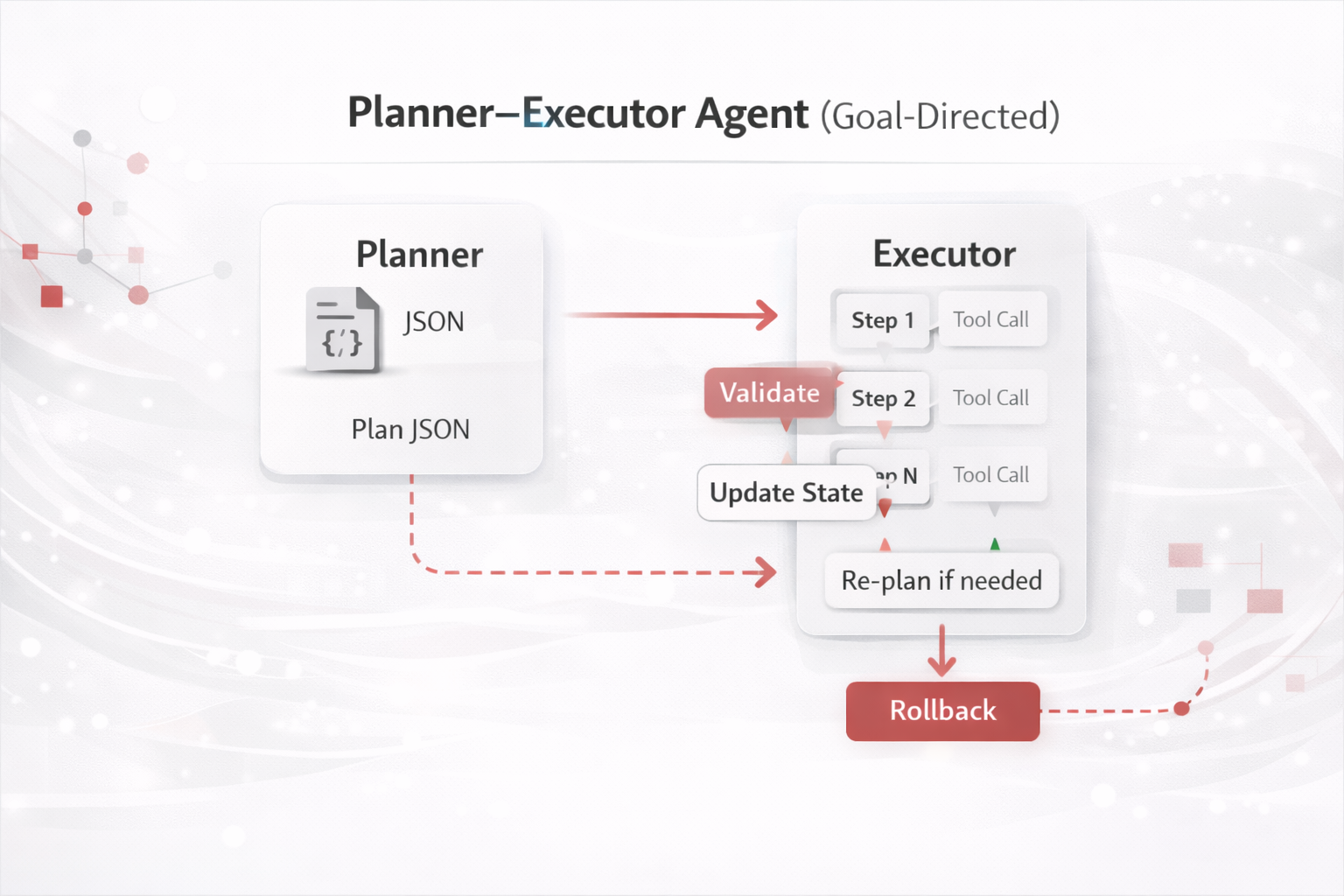
| Multi-step work with dependencies | 3) Planner–Executor | Creates traceable plans, checkpoints, and controlled execution. |
| High-stakes output quality | 4) Reflection Loop | Improves reliability via critique + revision gates. |
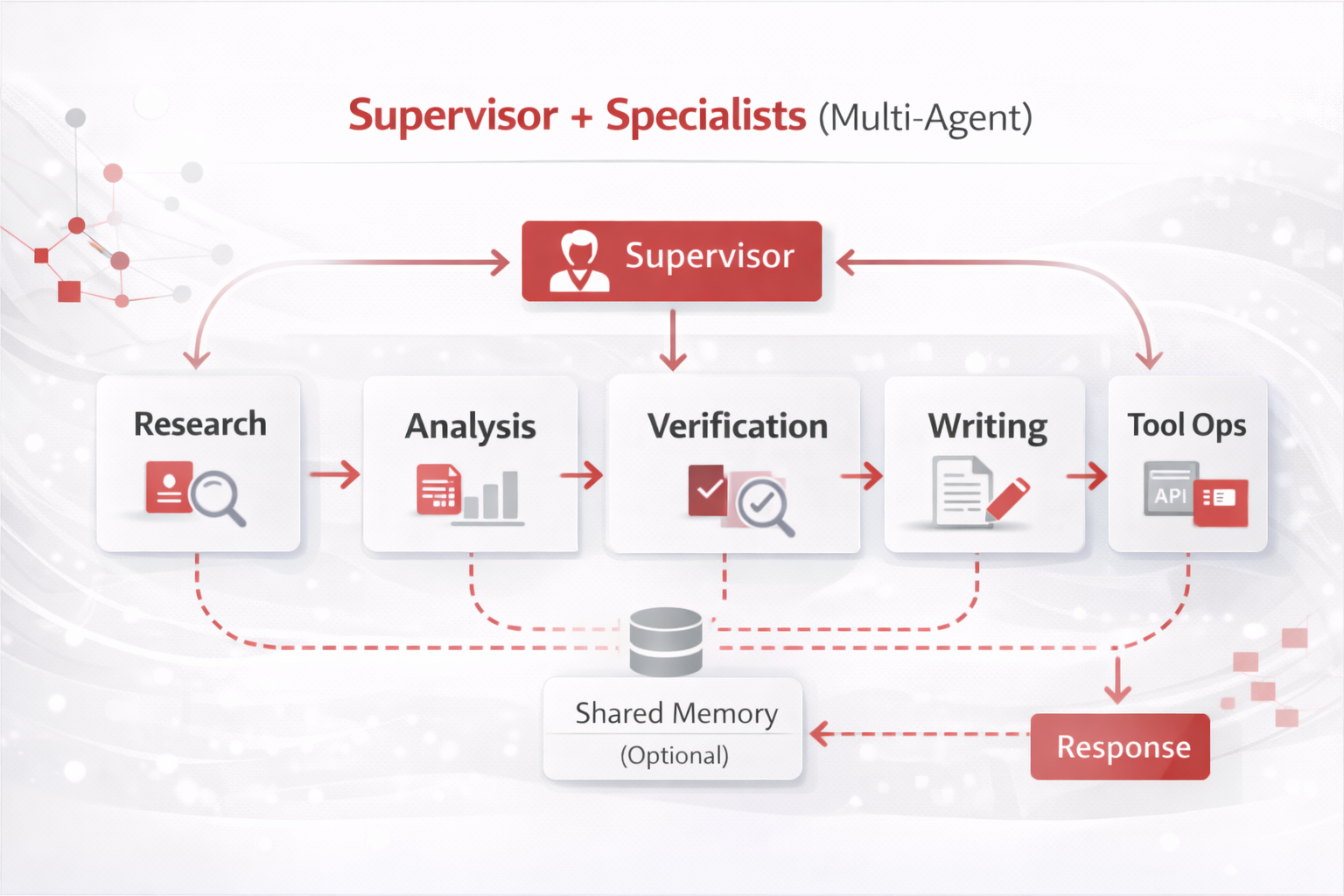
| Complex work needing multiple skills | 5) Supervisor + Specialists | Parallelism + modularity; better separation of concerns. |